History
The Term “RAID” was used in 1987 by David Patterson, Garth A. Gibson and Randy Katz at the University of California, Berkeley in 1987. In their 1988 report, “A Case for Redundant Arrays of Inexpensive Disks (RAID)” they argued that the mainframe disk drives performance can be beaten by RAID. By configuring redundancy, the reliability is beyond to any extent single drive.
RAID
The term RAID related to hard disk management technique mostly for server side. RAID is a data storage virtualization technology that combine multiple hard disk into a single logical unit for data redundancy, reliability and performance improvement. It has used mirroring, stripping and/or parity to achieve the RAID configuration. Once the RAID is setup, it forms a single logical disk for the operating system.
Stripping
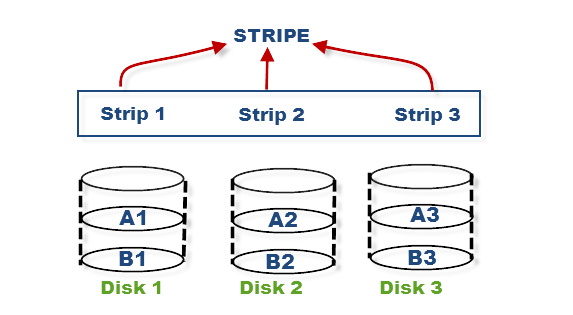
In Stripping, hard disk divided into blocks and these blocks are stacked together and called strips. With multiple hard disks placed parallel or serial, we can achieve the stripe. Without mirroring and parity, Stripping cannot have safe data but stripping may significantly improve the I/O performance.
Mirroring

Mirroring is most trusted method for data protection in RAID. This is straightforward way to understand as it copies identical data onto more than one drive in real time. It most commonly used in RAID 1. In case the first disk failure, the controller uses the second disk to serve the date, and it makes the data available continuously without any disruption.
When the failed disk is replaced with a new disk, the controller copies the data from the surviving disk of the mirrored pair. Data is simultaneously recorded on both the disk. Though this type of RAID gives you highest availability of data but it is costly as it requires double amount of disk space and thus increasing the cost.
Parity
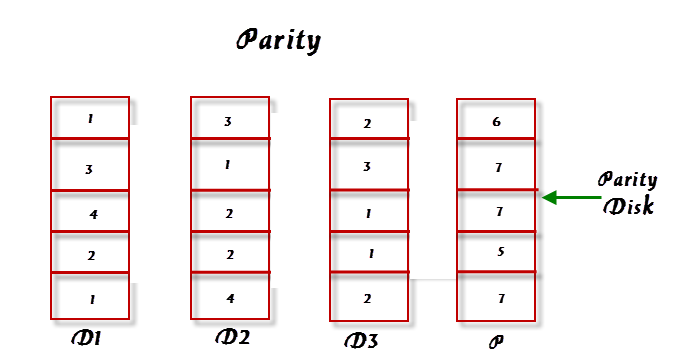
This is reliable and low-cost solution in RAID for data protection. In this method, an additional disk is added to stripe width to hold parity bit. Parity used for fault tolerance by calculating the data in two drives and storing results on third drive. RAID 3 used parity disk for fault tolerance and fast data stripping.
The parity bits are used to recreate the data during the disk failure. Parity information can be stored a separate disk or can be stored across all disks.
RAID Controllers
A RAID controller is a hardware or software program used to manage the hard disks in storage array so that they can be as a logical unit. RAID controllers bridge between the operating system and the hard disks.
In hardware-based RAID, physical controller is used at motherboard or at separate RAID card to present the data to the applications and operating systems as logical units. The controller resides on a PCI bus.
In Software RAID performs the processing on the host’s CPU. Thus, it gives a cheapest possible solution. The difference between the hardware RAID and software RAID is where the RAID processing happens. Software-based RAID does not use the server processor and hardware-based RAID provides better performance. Hardware-based RAID is more expensive than software based RAID due to its additional hardware.
Standard RAID levels
RAID 0
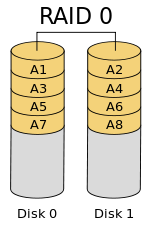
RAID 0 knows as stripping. Data split and stored across two or more disks, without any parity, redundancy or fault tolerance. Since RAID 0 has no fault tolerance, the failure of one disk will cause the entire array to fail.
- Minimum 2 disks.
- No redundancy
- Do not use for mission critical applications.
RAID 1
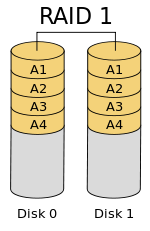
In RAID 1, data is writing simultaneously in two disks. It consists of exact set of data (mirror) on two or more disks. If one disk failed, the data can be retrieved from the other disk.
This layout is useful when read performance or reliability is more important than write performance or the resulting data storage capacity.
- Minimum 2 disks.
- Excellent redundancy
- Good performance
- Do not use for mission critical applications.
RAID 2
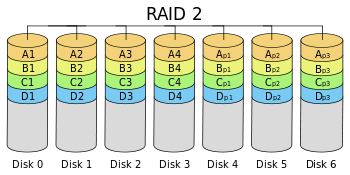
RAID 2 is rarely used in practice, it stripes data at the bit level rather than block level. It uses a hamming code for error connection.
RAID 3
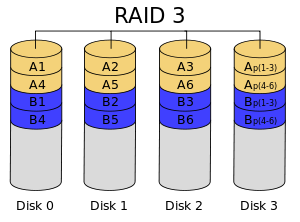
RAID 3 also rarely used in practice, it stripes data at the byte level with a dedicated parity disk. RAID 3 cannot serve multiple request simultaneously.
RAID 4
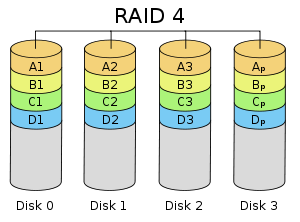
RAID 4 stripes data at the block level with a dedicated parity disk. RAID 4 provides superior performance of random reads, while the performance of random writes is low due to the need to write all parity data to a single disk.
RAID 5
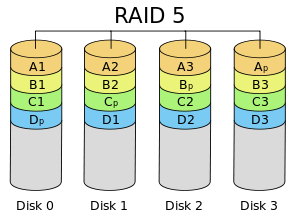
RAID 5 consist of block level stripping with distributed parity. In RAID 4 parity information is distributed among the disks. It requires that all drives but one be present to operate.
Upon failure of a single drive, subsequent reads can be calculated from the distributed parity such that no data is lost.
- Minimum 3 disks.
- Good redundancy
- Good performance
- Use for databases that is heavily read oriented. Write operation is slow.
RAID 10
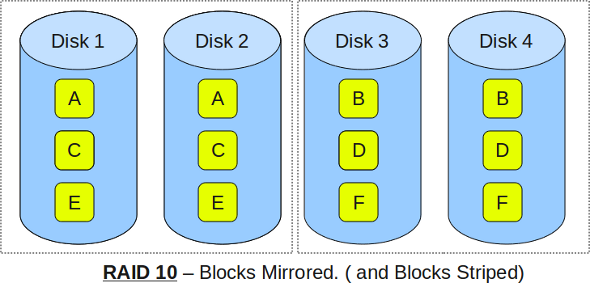
RAID 10 also known as RAID 1+0. It combined disk mirroring and disk stripping to protect the data. If one disk in each mirrored pair is functional, data can be retrieved.
- Minimum 4 disks.
- Excellent redundancy
- Excellent performance
- Best option for mission critical applications especially databases.
